How to Crawl Large Websites using Screaming Frog
One of the first steps when conducting an SEO audit or preparing for a website redesign is crawling (aka scraping) the website. Crawling a website can provide crucial information about potential issues and possible areas of improvement.
My personal tool of choice for crawling a website is Screaming Frog. It’s inexpensive, easy to use, and extremely versatile. The default setup is great for tackling websites with less than 10,000 pages, but you can crawl much larger-even huge-websites by implementing these configuration tips:
- Increase your computer’s RAM
- Increase the RAM available for Screaming Frog
- Increase the crawl speed
- Segment the website into crawlable chunks
- Target specific directories
- Exclude unneeded URLs
Why crawl a website?
There are many different things you can accomplish using Screaming Frog. Below are a few of the uses I find particularly helpful.
- Create a list of all URLs/pages on a website
- Find 302 redirects
- Perform QA for 301 redirect implementations
- Verify Google Analytics is located on every page
- Find broken links (internal and external)
- Find missing meta content and alt attributes
- Find duplicate content
- Find or verify Schema content
- Find malware or spam
- Find slow-loading pages
- Create an XML sitemap
- Validate a list of PPC URLs
Again, this is just a small list of the potential uses for crawling a website. There are many more things you can do once you get a full understanding of Screaming Frog’s capabilities.
How do you crawl a very large website?
Screaming Frog’s default setup is great for tackling websites with less than 10,000 pages, but what do you do when you run into a website like the one below?
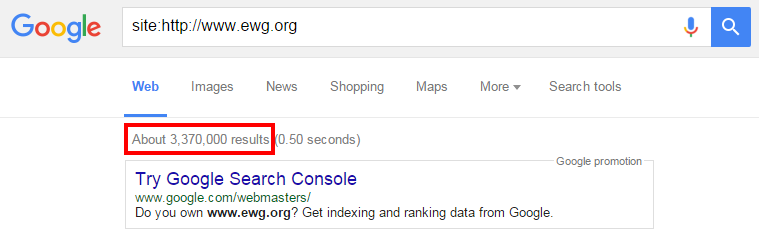
The website pictured has over 3 million indexed pages, which makes crawling it a challenge, to say the least. Taking on a website this size requires several important tweaks to Screaming Frog’s configurations. The following is a tutorial for setting up Screaming Frog to crawl very large websites.
1. Increase Computer RAM

This step is optional but extremely recommended. The Screaming Frog software relies on RAM for holding data during a website crawl. The more RAM your computer has, the more pages you can crawl. The good news is RAM has become extremely inexpensive. For most computers, an 8 GB memory card costs around $50.
You’ll need to do a little research on how much RAM your computer can hold since it ranges anywhere from 4 GB to over 64 GB. Once you know how much RAM you can add, make sure you purchase RAM cards that are compatible with your computer.
Installing RAM usually takes about 30 seconds. All you do is pop off the back of the computer and slide the RAM cards into the available slots. You may want to perform a quick search on YouTube for your computer model + “RAM Upgrade” to find a tutorial on how to perform the process in case there are specific nuances with your computer.
The best part about increasing RAM is it enhances more than just your ability to crawl websites. If you’re like me and you always have an assortment of programs running simultaneously while bouncing back and forth between 1,000 different Chrome tabs, you’ll be pleasantly surprised by the improvement in day-to-day computer speed.
2. Increase Screaming Frog’s RAM Availability
The default setting for Screaming Frog allows it to access 512 MB of RAM. Adding more RAM to your computer won’t change how many pages you can crawl until you alert the software it can use more of the available storage.
To do this, you’ll first need to open the folder Screaming Frog was downloaded to. Then use a text editor like Notepad to open the file named ScreamingFrogSEOSpider.l4j.
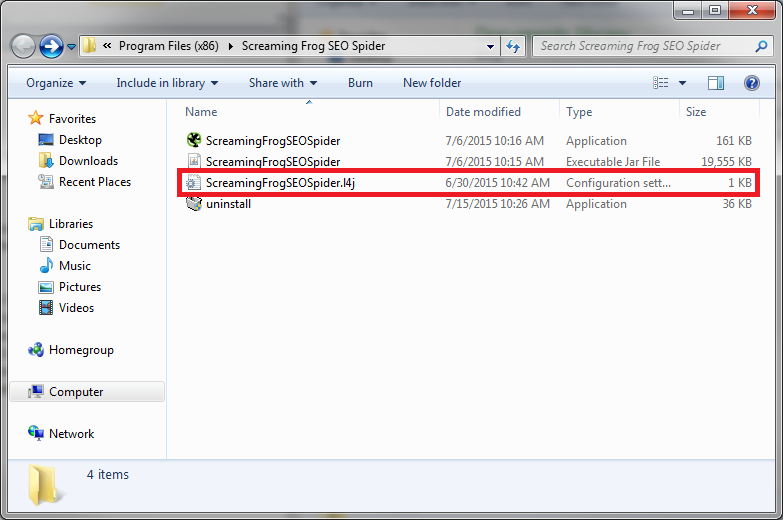
The file is very simple and only includes two lines of information. The number located on the second line is the one you’ll need to update.
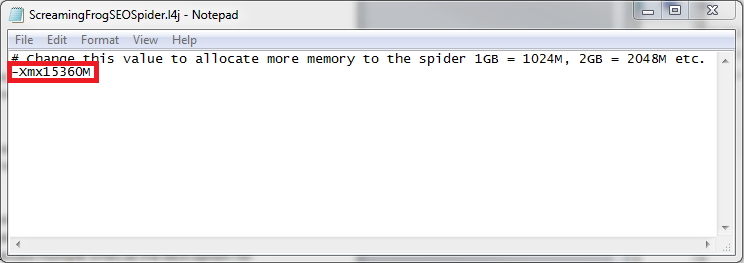
When you first open this file, the default number will be -Xmx512M. This means Screaming Frog is allowed to use 512 MB (0.5 GB) of your computer’s RAM. Add 1024 for every additional 1 GB of RAM you want Screaming Frog to have access to. For example, to allocate 15 GB (pictured in the above screenshot), replace the number with 15360 (1024 x 15 = 15360). Make sure to leave the -Xmx and M that appear around the number. Then save the file, and you should be ready to use your extra RAM.
TIP 1: I recommend allocating at least 3 GB less than your total available website RAM. If you allocate the full available website RAM, it’s possible for large website crawls to freeze your computer once it gets close to the maximum amount of RAM. For example, if your computer has 16 GB of RAM, only allow Screaming Frog to access 13 GB. You can always reduce the amount of RAM in this buffer if you determine it’s more than your computer actually requires.
TIP 2: To check if you successfully increased the RAM allocation, restart Screaming Frog, click on Help, and then Debug. Your new amount of RAM in the line labeled Memory should be listed directly behind the word Max.
3. Increase Screaming Frog’s crawl speed
Crawling large websites does take time, but there are ways to help expedite the process. You’ll need to increase the crawl speed in the configuration tab to minimize the time it takes.
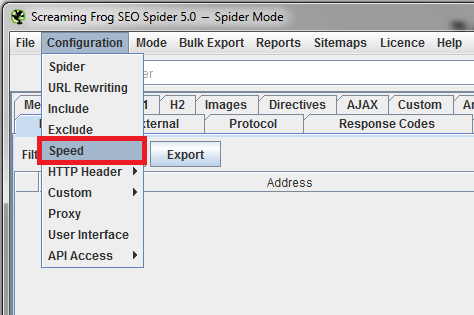
Once you click on Speed, the spider speed configuration box will appear. The number next to Max Threads determines how quickly you can crawl a website.
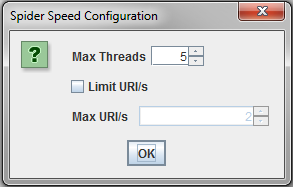
Increasing this number will greatly improve the time it takes to crawl websites. Test using a few different max thread counts and see how the crawl speed is affected (Ex. 10, 50, 100, 200, 500, 1000, etc.)
It’s worth noting that setting a high number of threads will increase the number of HTTP requests made to the server, which can impact the website’s response times. I’ve never run into this issue with any of our clients, but it doesn’t hurt to reach out to the site’s webmaster to approve a crawl rate just in case. Another option is to monitor response times and adjust the speed if you notice any issues.
4. Segment the website into crawlable chunks
No matter how much RAM you put into your computer, there will always be some websites with too many pages to crawl in one session. To crawl websites of this size, you’ll need to segment them into crawlable chunks.
You’ll first need to run a test crawl to find the maximum amount of URLs your computer can handle. The maximum amount of URLs you can crawl will help determine your segmentation strategy. As a reference, in my experience, a computer with 15 GB of RAM allocated to Screaming Frog can crawl 600,000-900,000 URLs per session.
After determining your maximum number of URLs, you’ll need to map out the website by breaking it into subdomains or directories that fall below your maximum URL count. Use a site search command in Google to determine the number of indexed pages in each section (ex: Site: http://yourdomain.com/targeted-directory/).
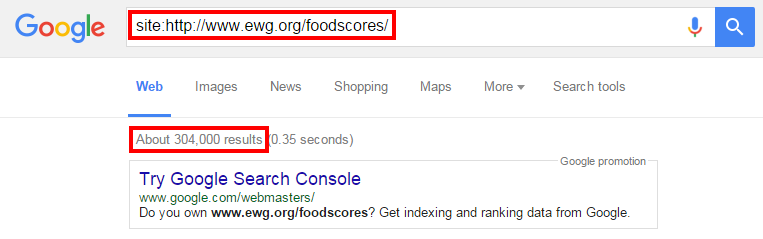
As you can see in the screenshot above, this directory only includes 304,000 indexed pages, even though the website as a whole included over 3 million.
It’s important to note the site search command will only display the number of indexed pages in a directory. It does not display the total number of pages in a directory. Pages could exist in the directory that aren’t currently indexed. For that reason, give yourself a buffer between the maximum amount of pages your computer can handle and the number of indexed pages in the section you’re trying to crawl. For example, if your computer can handle around 700,000 pages per crawl, then try to segment the website into sections that include 500,000 or fewer indexed pages. This will give you a 200,000-page buffer to account for any non-indexed pages.
Tip: You may run into a subdomain or directory with more indexed pages than your computer can crawl. An explanation for how to handle that situation is included in section 6 of this tutorial.
5. Include target directories
The next step in the setup process is to let Screaming Frog know what specific content you want to crawl. You’ll need to click on Include in the configuration drop-down.
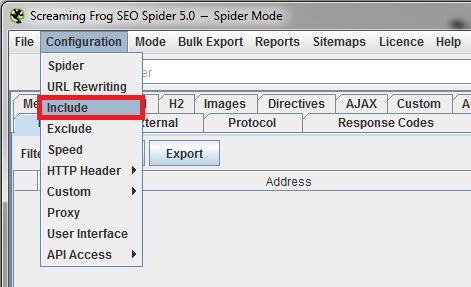
A box will open that allows you to use regular expressions (regex) to limit the crawl to certain content. If you’re unfamiliar with regular expressions, Microsoft has a pretty good list of what each character can be used for.
The example below shows the regular expression used to limit a crawl to only the /foodscores/ directory.
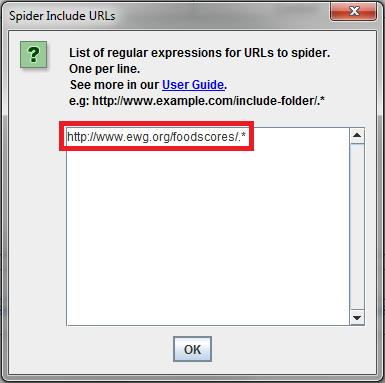
It’s important to begin the crawl from a page with at least one internal link pointing to your target content. If not, your crawl will end after only one page.
6. Exclude unneeded URLs
The exclude feature is similar to the include feature except, as you may have guessed, it removes sections you don’t want in your results.
This is very helpful when breaking up websites with nested directories or breaking up the directories themselves when they have more pages than your computer can handle on one crawl.
This functionality is also extremely helpful when working with a CMS that auto-generates dynamic pages. If you start a crawl and you begin noticing a large number of the URLs being pulled in have dynamic segments like ?search= or ?tag=, you’ll most likely want to add those URL segments into the exclude section to clean up your results and reduce the number of unneeded pages crawled.
Below are a few regular expression examples of the exclude functionality that Screaming Frog highlights on their website.

TIP: It can sometimes be tricky to break up individual directories with more indexed pages than your computer can handle. You’ll need to leverage the include and exclude functionalities to accomplish this task.
One possible solution is to break up the directory by URL keyword usage. If a large portion of the URLs in a directory contain a specific keyword, you can use it to your advantage. Run one crawl including URLs in the directory that contain the targeted keyword, and then run a separate crawl where you include the directory and exclude the keyword.
The best solution to this problem usually depends on the specific website you’re trying to crawl. Spend some time getting familiar with regular expressions. You’ll discover many options for breaking up large directories into crawlable chunks if you do.
Additional tips
Here are a few additional tips for setting up Screaming Frog and crawling large websites.
- If you have a 64-bit machine, ensure you download and install the 64-bit version of Java. If you don’t, you’ll run into the error displayed below.
- Save crawl backups when getting close to your maximum RAM usage. For example, if your computer can usually handle 700,000 URLs per crawl and you’re in the middle of a crawl that just passed 600,000 URLs, it’s a good idea to pause and save in case the high RAM usage eventually causes your computer to freeze up. There’s a default setting in Screaming Frog that’s supposed to pause the software on high memory usage, but I’ve experienced situations where it doesn’t always work.
- As noted earlier, the more RAM your computer has available for Screaming Frog, the more URLs you can crawl. That means it can be helpful to reduce the amount of RAM your other programs require. If you use Chrome and keep many tabs open at once, a free extension called The Great Suspender temporarily freezes tabs you haven’t used in a while. It allows you to quickly unfreeze the tabs whenever you need them again. The extension helps reduce Chrome’s RAM usage, and I have found it extremely beneficial.
Crawling huge websites can certainly be a challenge, but it’s a process that’s vitally important for SEO, website maintenance, and during the redesign process. Luckily, once you’ve implemented all the above configurations, you’ll be ready to start crawling websites the size of Mount Everest.
Do you have your own tips for crawling large websites? Or do you have additional questions? Feel free to post your questions and comments below or reach out to me directly at: [email protected] or @BrianRogel
Good luck, and happy crawling!
Did you read this entire blog post? If so, we’re impressed with your dedication (let’s be honest, it’s quite a lengthy post.) You might be just the type of person we’re looking to hire. Be sure to check out our open positions and reach out to us. We look forward to hearing from you!